




Data Processing
Distributed Data Processing
- Distributed data processing allows multiple computers to be used anywhere in a fair. One computer is designated as the primary or master computer.
- Distributed data processing is in contrast to a single, centralized server managing and providing processing capability to all connected systems.
- Computers that comprise the distributed data-processing network are located at different locations but interconnected by means of wireless links.
Business Challenges of Distributed Data Processing
- Complexity: Systems attached in distributed data processing are difficult to troubleshoot, design and administrate.
- Data Synchronization is Cumbersome: Data synchronization is difficult to develop in distributed data processing. Sometimes data is updated in wrong order hence administrators need to focus on it before making a distributed network.
- Data Security: Computer performance is affected & data can be lost f an unauthorized computer is connected to a distributed network.
Business Benefits of Distributed Data Processing
- Lower Cost: Distributed data processing done by connecting personal computers from different locations can save money. Data is also distributed so adding and removing nodes (computers) can be easy.
- Easy Replacement of Remote Systems: In distributed data processing If any computer on the network fails or corrupted by some means then that computer is automatically replaced by other computers.
- Optimized Processing: Managing data on online server solves slow processing. Database server can only handle database queries and file server stores files. Hence data processing is optimized.
- Parallel Processing: Parallel processing means data is updated at the same time from all nodes. Adding and removing computers from the network cannot disturb data flow. All data from different computers are processed in parallel.
Key Big Data Tools/Technologies
Apache Hadoop
- Apache Hadoop is an open-source framework designed for distributed storage and processing of very large data sets across clusters of computers. Apache Hadoop consists of components including:
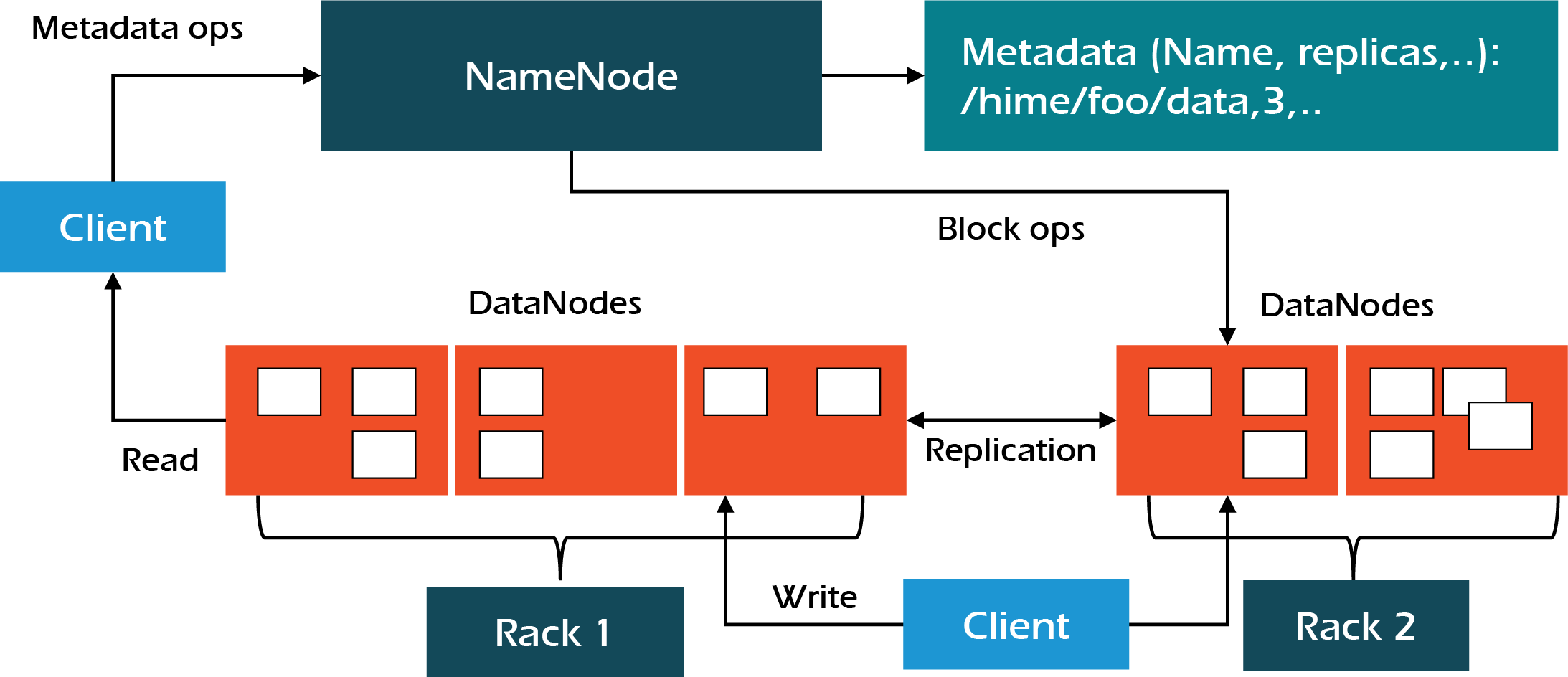
- Hadoop Distributed File System (HDFS), the bottom layer component for storage.
- HDFS breaks up files into chunks and distributes them across the nodes of the cluster. Yarn for job scheduling and cluster resource management.
Architecture
Apache Zookeeper
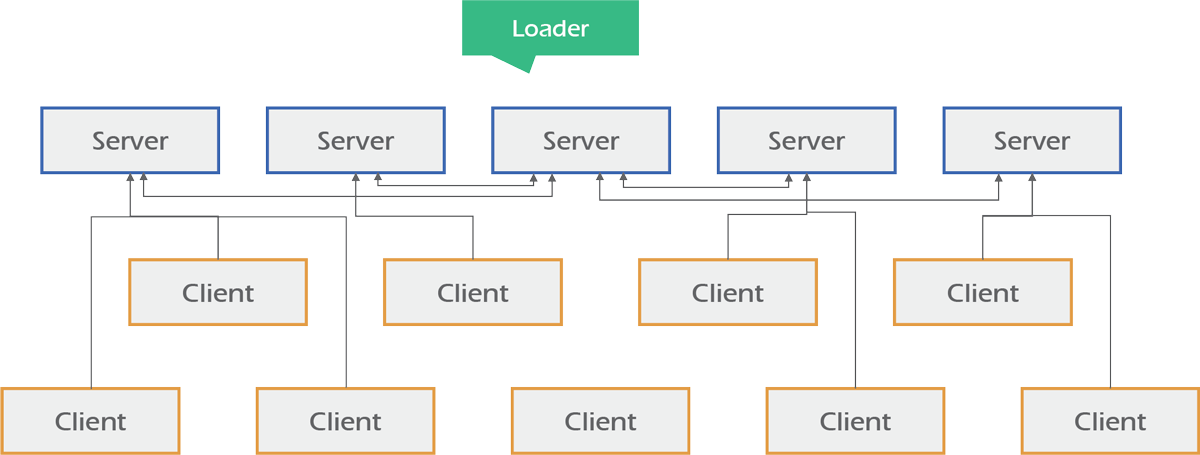
- Apache ZooKeeper is a centralized service for configuration management, naming, providing distributed synchronization and providing group services.
- It simplifies management of the servers on which Hadoop is running and reduces the risk of inconsistent settings across servers.
Architecture
In-Memory Data Processing
In-memory data processing is the process of processing data entirely in computer memory (e.g., in RAM) rather than disk processing. This is different to other techniques of processing data which rely on reading and writing data to and from slower media such as disk drives.
- In-memory processing typically implies large-scale environments where multiple computers are pooled together so their collective RAM can be used as a large and fast storage medium.
- In-memory data processing works by eliminating all slow data accesses and relying exclusively on data stored in RAM.
- In-memory data processing is extremely popular today because of its huge performance advantage over processing techniques that require reading and writing to slower media.
Business Challenges of In-memory Data Processing
- The main challenge of in-memory data processing is its reliance on computer systems. If something were to happen to a computer, especially to the RAM or flash memory, then data is compromised. Hence, information is not as secure in-memory compared to on disk.
- The other challenge is control cost. Memory-based systems are incredibly expensive compared to their disk-based systems.
Business Benefits of In-memory Data Processing
- In-memory data processing avoids the go and get step completely, because for analytical purposes all the relevant data is loaded into RAM memory all the time, and therefore does not have to be accessed from disk storage.
- With In-memory data processing businesses can analyse large datasets in real-time, which generates better insights from data analytics.
- With in-memory data processing, storage of structured & Unstructured data is hassle free. It is easier to store both structured and unstructured data now. Thus, it is easier to get richer and deeper insights from data analytics.
Key General Tools/Technologies
Tableau Data Extract
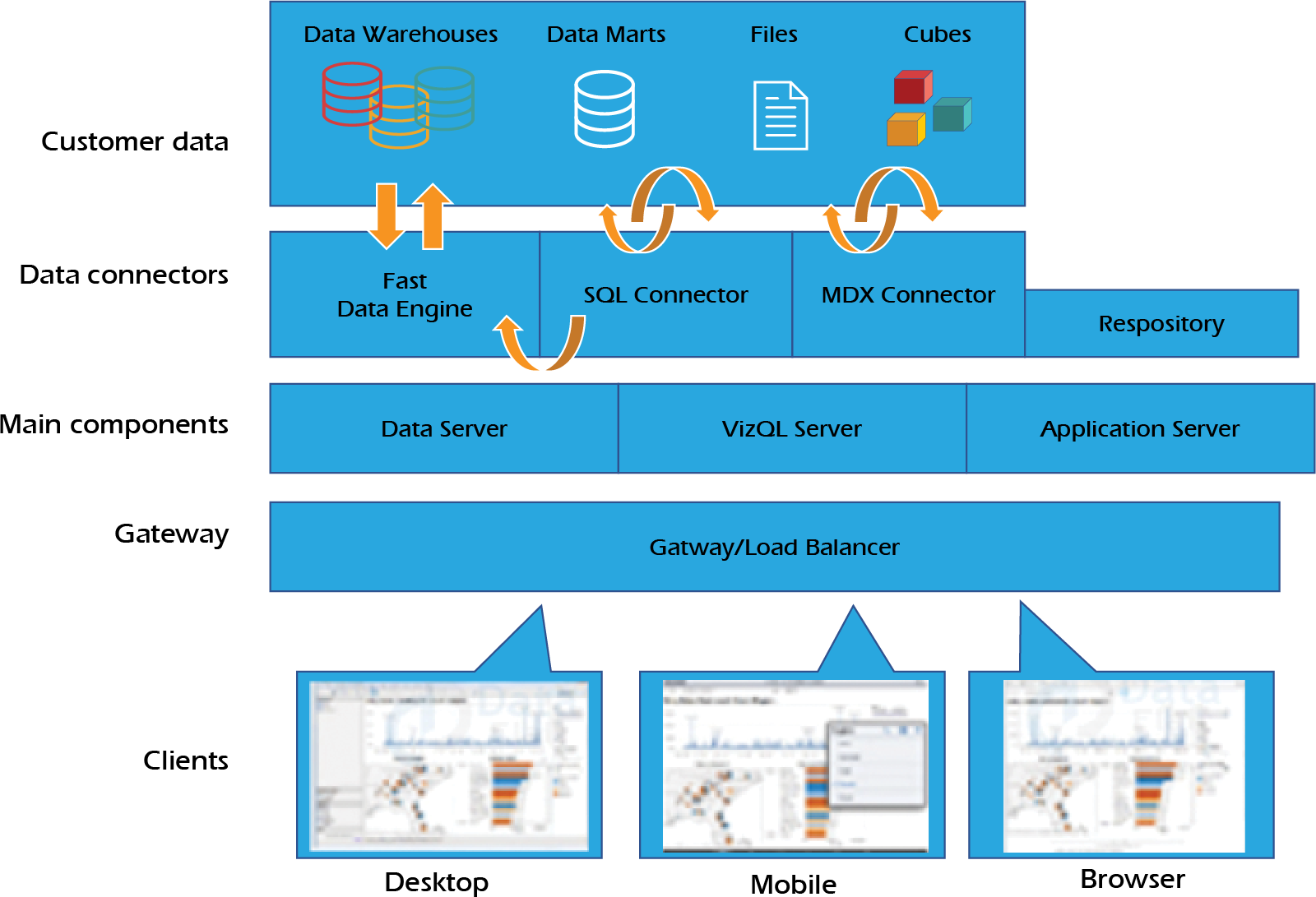
- Tableau data extract is a compressed snapshot of data stored on disk and loaded into memory as required to render a Tableau.
- Tableau combines in memory and live direct connections.
- The Tableau Data Engine is a high-performing analytics database on your PC that enables ad-hoc analysis in memory of millions of rows of data in seconds.
- Tableau’s architecture-aware design represents the next generation of in-memory solutions: by using different levels of memory at different times, it lets you take advantage of the computing power on every PC without limiting the size of the data to fit in memory.
Architecture
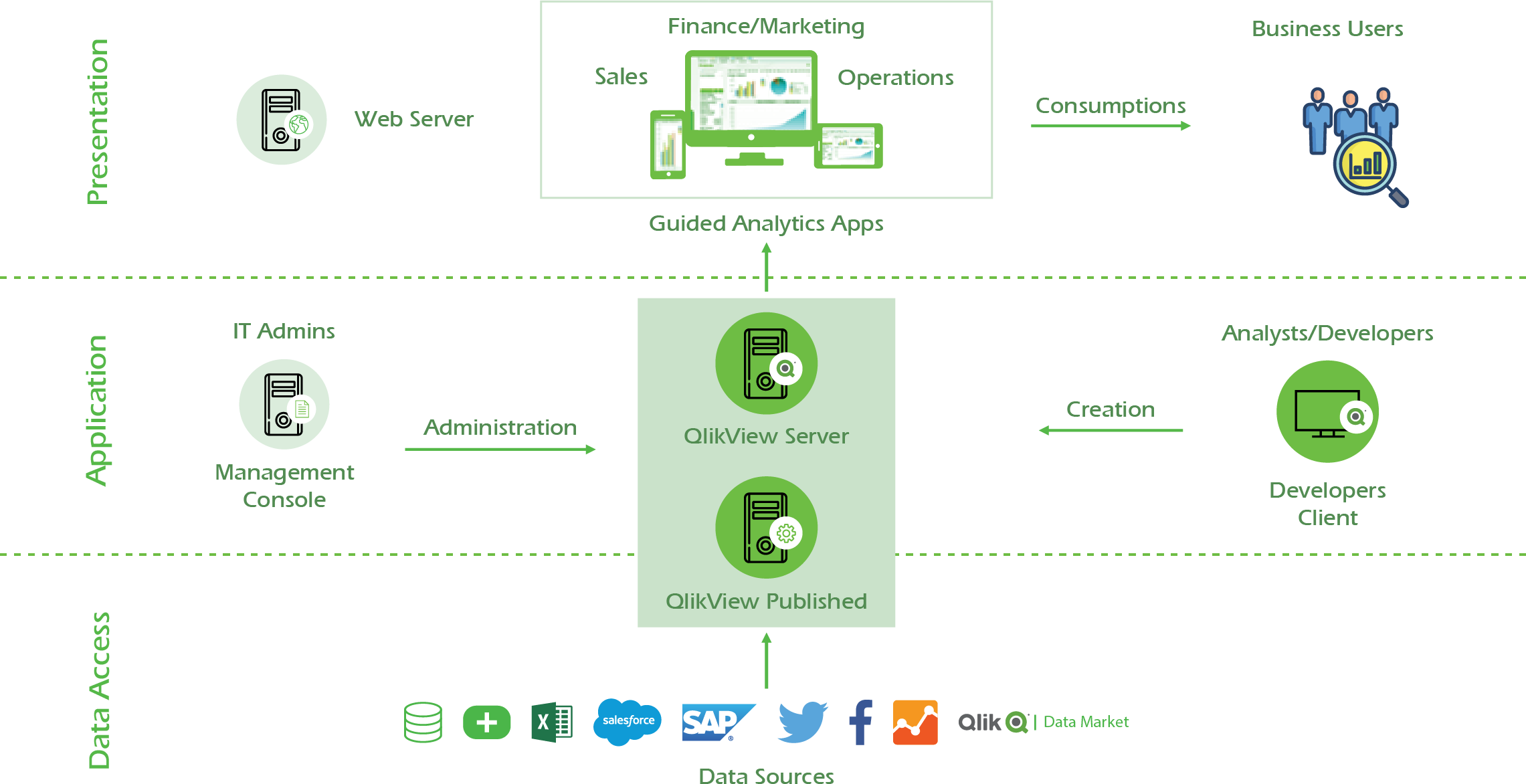
Qlikview
QlikView uses in-memory technology to allow users to analyze and process data very quickly. Unique entries are only stored once in-memory: everything else are pointers to the parent data. That’s why QlikView is faster and stores more data in memory than traditional cubes.
Architecture
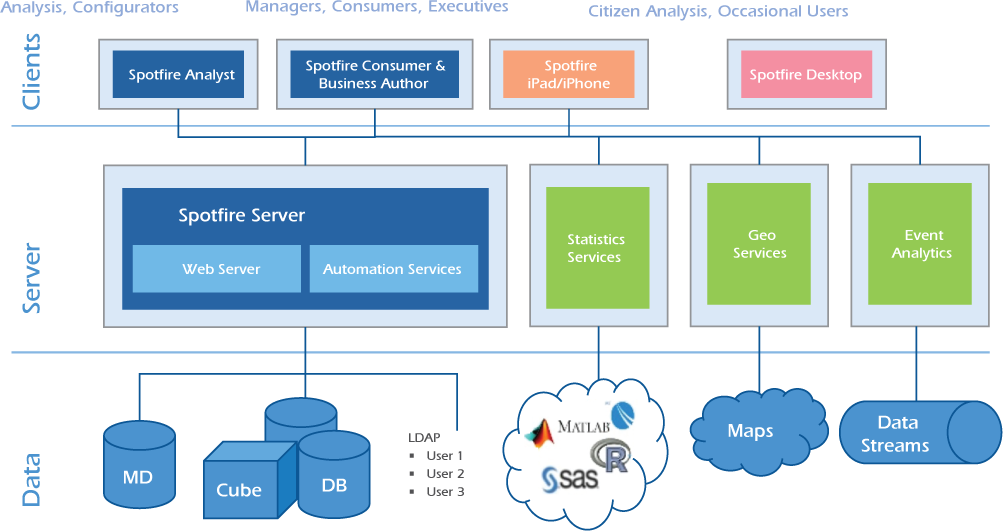
Tibco Spotfire
Tibco’s Spotfire In-memory processing engine eliminates the “go get” data step completely, because for analytical purposes all the relevant data is loaded into super-speedy RAM memory all the time, and therefore does not have to be accessed from disk storage. So the time factor changes dramatically. Also, it’s possible to see the data more flexibly and at a deeper level of detail, rather than in pre-defined high-level views.
Architecture
Key Big Data Tools/Technologies
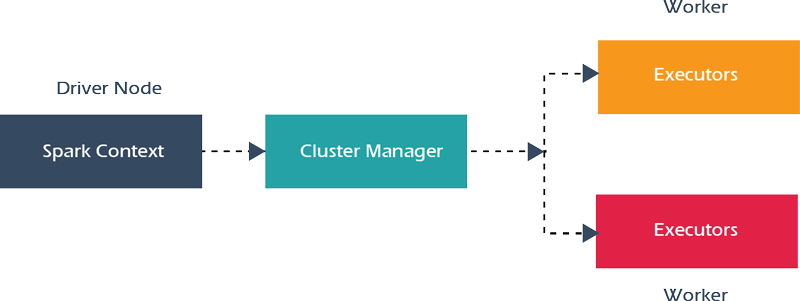
Apache Spark
- Apache Spark is a powerful unified analytics engine for large-scale distributed data & in memory processing (data collection, integration etc) and machine learning.
- Apache Spark integrates into existing workflows to automatically make data validation a vital initial step of every production workflow.
- Apache Spark is aimed at data scientists and data engineers, who are not necessarily Scala/Python programmers.
Architecture
Usecases
- Patient Records Analysis: Apache Spark is used in healthcare for patient clinical record Analysis. It helps to identify which patients are likely to face health issues at a later stage after discharge from the hospital. This prevents the patient hospital re-admittance.
- Real-Time Transaction Analysis: Apache Spark helps in providing with Information about a real-time transaction. It also helps to enhance the recommendations to customers based on new trends. Some Real-time examples like Alibaba, eBay using Spark in retail world.
- Credit Risk Assessment: Apache Spark helps in credit risk assessment targeted advertising and customer segmentation. Apache Spark helps in accessing the social media profiles, emails, forum, call recordings and many more.
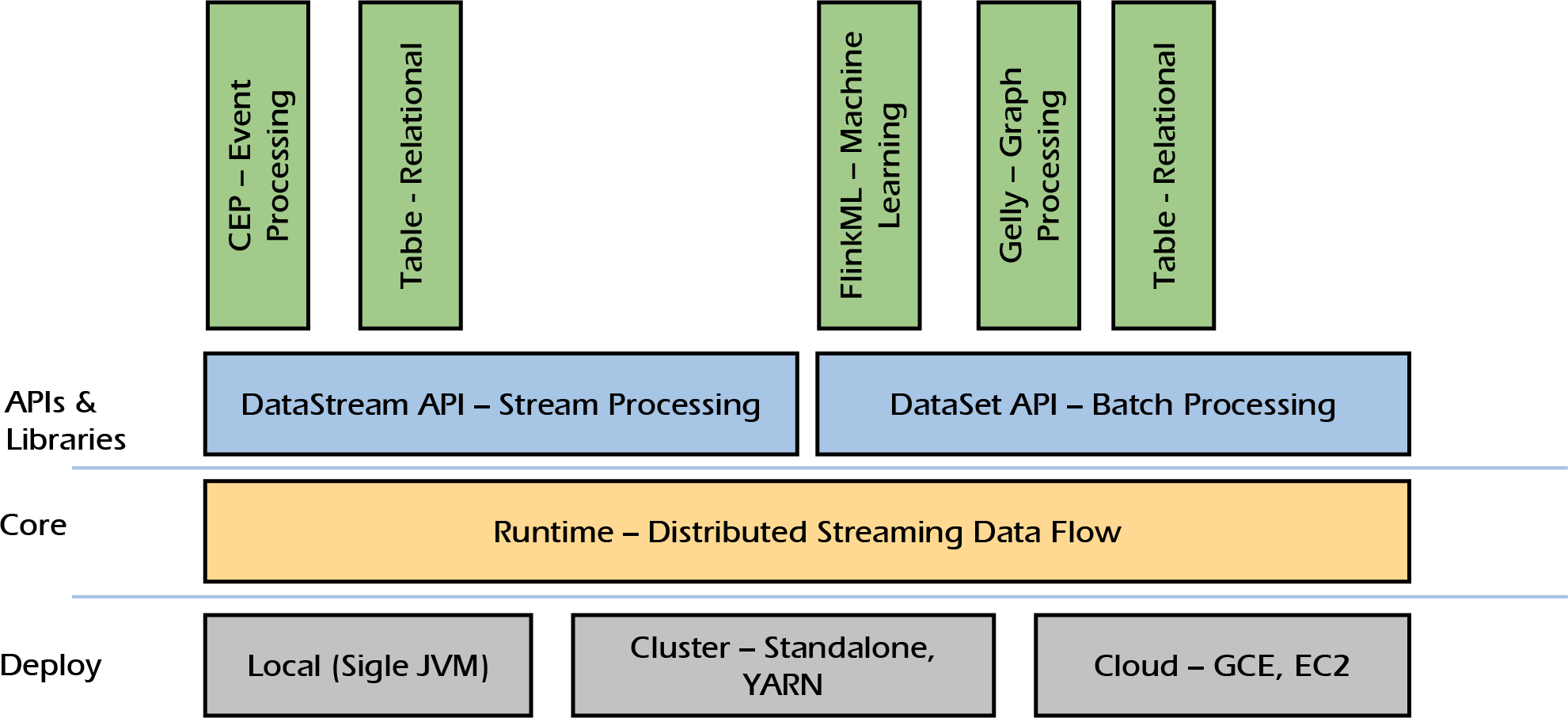
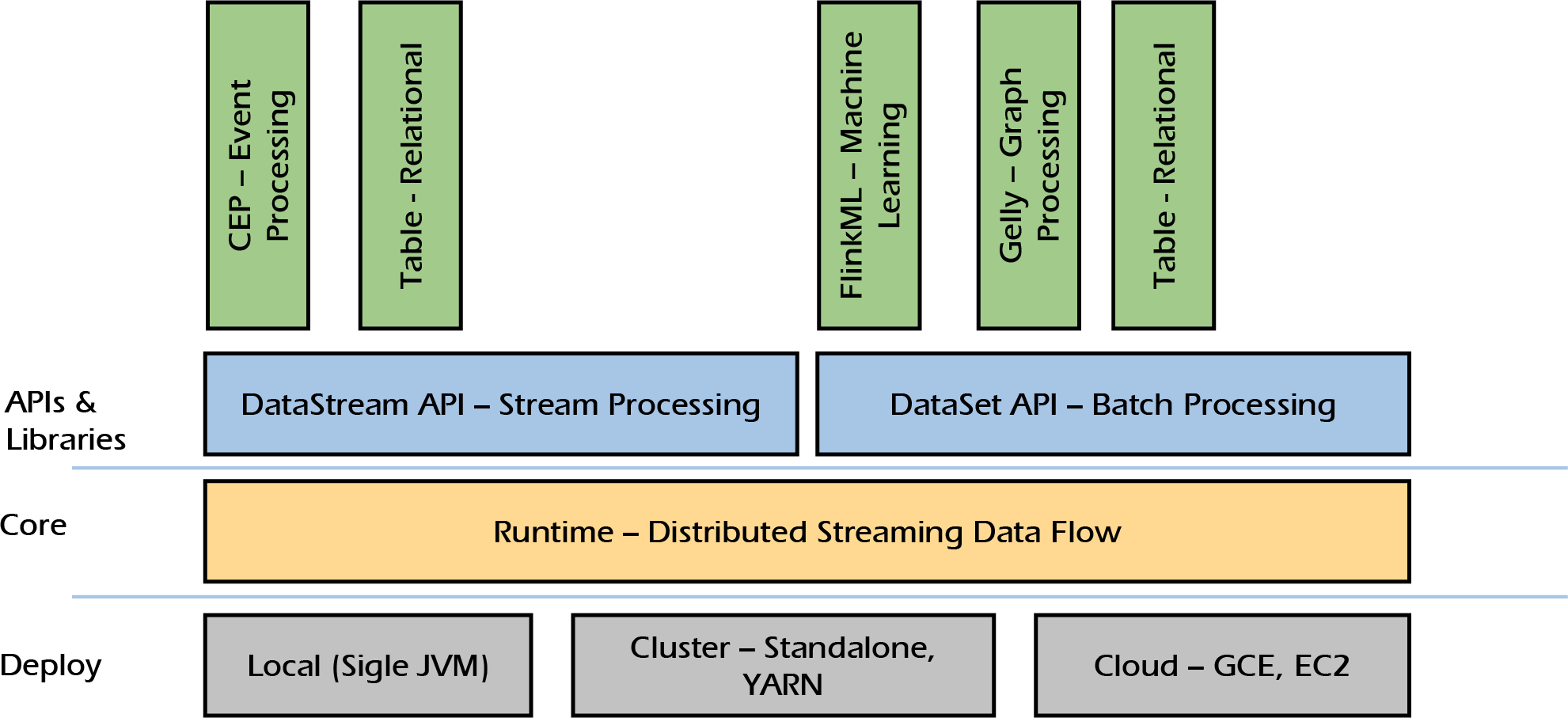
Apache Flink
- Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams.
- Apache Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
- Apache Flink is designed to run stateful streaming applications at any scale. Applications are parallelized into possibly thousands of tasks that are distributed and concurrently executed in a cluster.
Architecture
Usecases
- Search Engine Optimization: Apache Flink is used in search engine to show results in real-time with highest accuracy and relevancy for each user.
- Real-Time Process Monitoring: Apache Flink is used for real-time process monitoring. A stream-based architecture nicely supports a microservices approach, and Apache Flink provides stream processing for business process monitoring and continuous Extract, Transform and Load (ETL).
- Customer Activity Monitoring: Apache Flink is used in detecting and resolving customer issues immediately and enable flawless digital enterprise experience.
Key Enterprise Tools/Technologies
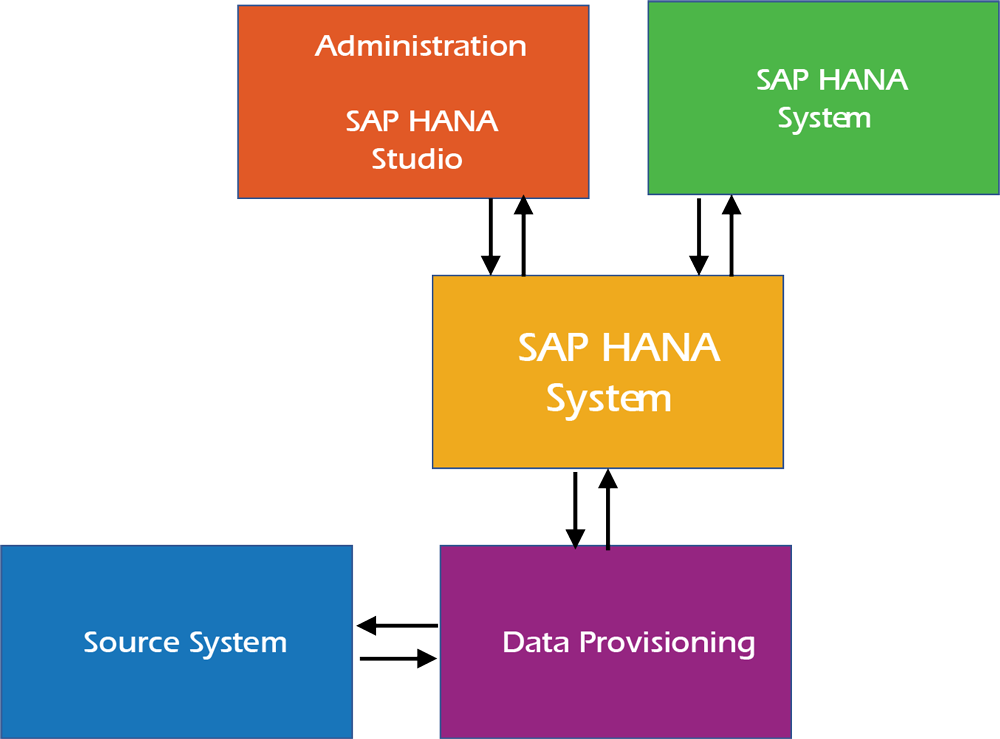
SAP HANA
- SAP HANA is an in-memory computing technology which comprises of both hardware and software to process large amounts of real-time data.
- It is a platform which you can deploy both on-premise as well as on the cloud. Here, everything from developing applications to performing analysis achieves in real-time because of the in-memory computing.
- SAP HANA provides a multi-engine query processing environment where multi-core CPUs, multiple CPUs per board and various boards on an application server are used.
- It makes data processing about a million times faster than that from the disk.
Architecture
Usecases
- Information Processing: SAP HANA to gather information about nuclear-aircraft carriers and create 3D models using it. Also, Airbus uses S/4 HANA for instant information processing, analysis and reporting.
- Customer Information Analysis: SAP HANA is used to analyze the customer information, requirements and market trends to improve in business. SAP HANA is also used in maintaining and monitoring a business model which is a must to stay in the competition.
Real Time Data Processing
- Data processed or execution of data in short period of time is called as Real-Time Processing. The processing is done as the data is inputted, so it needs a continuous stream of input data in order to provide a continuous output.
- Stream Processing is also called as Real-Time Data Processing.
- Real-Time Data Processing depends on continuous flow of input data which is processed by a system to provide a continuous output.
Business Challenges of Real-Time Data Streaming
- As the processing happens in real-time precautions must be taken to protect the contents of backup files of the databases.
- More number of measures have to be incorporated into the hardware & software procedures to protect the data from unauthorized access.
Business Benefits of Real-Time Data Streaming
- Real-Time Data Processing provides immediate updating of database and immediate responses to user defined queries.
- Real-Time Data Processing uncovers the operational problem within an organization. This helps the organization from falling behind or save the customers from leaving its business.
- Real-Time Data Processing gives insights into new strategies so that the organizations can remain one step ahead of the rest of the competitors.
- Real-Time Data Processing is important for applications where a high frequency of changes are made during a short time to keep it updated.
- Only specific records affected by transactions or inquiries need to be processed & databases can be processed or updated concurrently.
Key Big Data Tools/Technologies
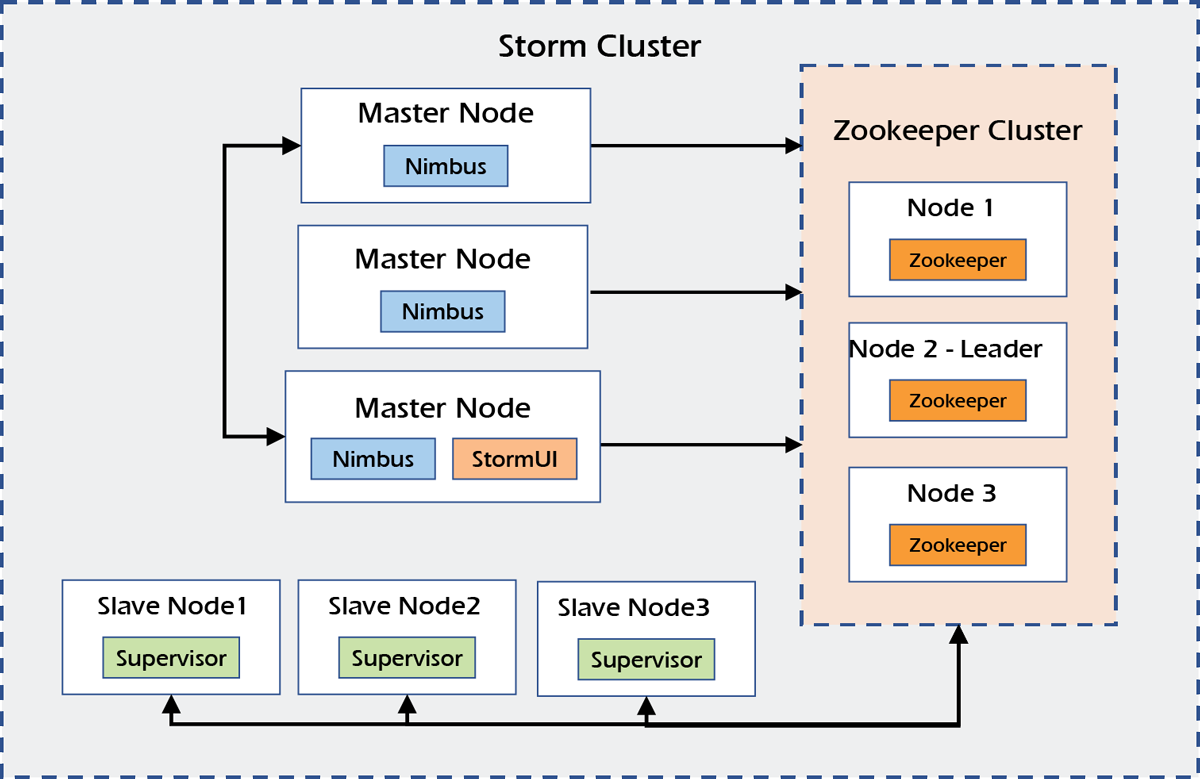
Apache Storm
- Apache storm is a system for processing streaming data in real time.
- Apache Storm is a distributed real-time computation system for processing large volumes of high-velocity data.
- Apache Storm is extremely fast, with the ability to process over a million records per second per node on a cluster of modest size.
Architecture
Usecases
- Twitter Analytics: Apache Storm is used to power a variety of Twitter systems like real-time analytics, personalization, search, revenue optimization and many more.
- Metasearch Engine Analytics: Apache Storm streams real-time metasearch data from affiliates to end-users. The topology concepts in Storm resolves concurrency issues and at the same time helps them to relentlessly integrate, dissect and clean the data. Additionally, the tools provided in Storm enables incremental update to enhance their data.
- Event Log Monitoring: Navsite is using Apache Storm as part of their server event log monitoring & auditing system. The log messages from thousands of servers are sent to RabbitMQ cluster and Storm is used to compare each message with a set of regular expressions.
Apache Spark
- Apache Spark is a powerful unified analytics engine for large-scale distributed data processing (data collection, integration etc) and machine learning.
- Apache Spark integrates into existing workflows to automatically make data validation a vital initial step of every production workflow.
- Apache Spark is aimed at data scientists and data engineers, who are not necessarily Scala/Python programmers.
Architecture
Usecases
- Patient Records Analysis: Apache Spark is used in healthcare for patient clinical record Analysis. It helps to identify which patients are likely to face health issues at a later stage after discharge from the hospital. This prevents the patient hospital re-admittance.
- Real-Time Transaction Analysis: Apache Spark helps in providing with Information about a real-timetransactions. It also helps to enhance the recommendations to customers based on new trends. Some Real-time examples like Alibaba, eBay using Spark in retail world.
- Credit Risk Assessment: Apache Spark helps in credit risk assessment targeted advertising and customer segmentation. Apache Spark helps in accessing the social media profiles, emails, forum, call recordings and many more.
Apache Flink
- Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams.
- Apache Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
- Apache Flink is designed to run stateful streaming applications at any scale. Applications are parallelized into possibly thousands of tasks that are distributed and concurrently executed in a cluster.
Architecture
Usecases
- Search Engine Optimization: Apache Flink is used in search engine to show results in real-time with highest accuracy and relevancy for each user.
- Real-Time Process Monitoring: Apache Flink is used for real-time process monitoring. A stream-based architecture nicely supports a microservices approach, and Apache Flink provides stream processing for business process monitoring and continuous Extract, Transform and Load (ETL).
- Customer Activity Monitoring: Apache Flink is used in detecting and resolving customer issues immediately and enable flawless digital enterprise experience.
